운영체제
[운영체제] Process and Threads
anstjwls
2024. 2. 9. 15:48
Process: 실행 중인 프로그램
- 실체: 프로그램이 실행되는 데 필요한 모든 것들을 저장하는 자료구조
- 분기나 JUMP가 없으면 기본적을 sequential로 실행
- 포함하는 것
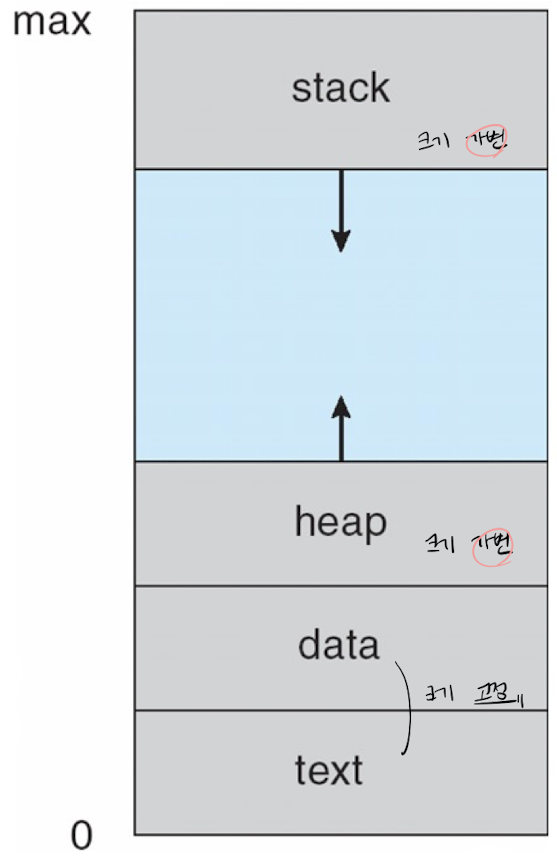
1. text section: 프로그램 코드
2. stack section: function call과 관련된 데이터들 (parameter, return address, local variables ...)
-> top에서 pop하면 함수에 들어갔다 나오는 정보들을 바로 알 수 있음
3. data section: 프로그램의 어떤 부분을 실행하든 접근 가능은 데이터들, static, global variable 저장
4. heap section: 동적 메모리 할당(ex> malloc)으로 저장한 데이터 관리하는 영역
5. 동작, 컨트롤, 상태 에 필요한 program counter, register 저장 영역이 따로 있음, 멀티프로그래밍, 멀티태스킹을 위함
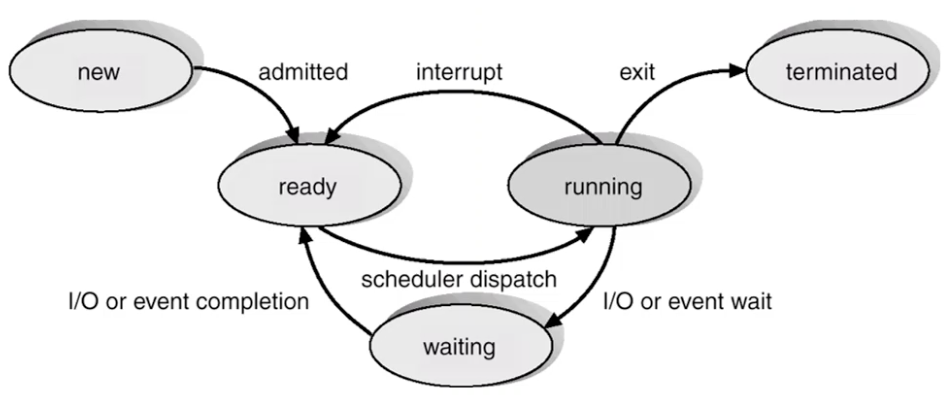
Process State
- new: 프로세스 막 만들어진 상태, 메모리 탑재, CPU 스케쥴링의 대상은 아님
- running: 프로세스가 현재 cpu를 잡고 일을 하는 상태
- waiting: 프로세스가 이벤트 발생을 기다리는 상태, 즉 I/O가 끝나길 기다리는 상태, I/O가 끝나야만 할당받을 수 있
- ready: 준비가 됐지만 cpu를 할당받지 못해서 일을 못 하고 있는 상태, 언제든지 cpu를 할당받을 수 있음
- terminated: 마지막 instruction까지 수행을 끝낸 상태, OS는 이 프로세스를 free 시켜버림
Process Control Block (PCB)
-> 프로세스의 형태를 갖추게 하는 자료 구조 (Linux에서는 task_struct)
Process state, program counter, CPU registers, CPU 스케쥴링, 메모리 관리, accounting, I/O 상태 정보 등을 포함
Process Scheduling Queues
-> 상태별 프로세스가 모여있는 장소
- Job Queue: 모든 프로세스 관리
- Ready Queue: ready 상태의, CPU를 기다리는 프로세스들이 모여있는 장소
- Device Queues: 인터럽트 기다리는, wait 상태의 프로세스 관리
- 프로세스의 상태가 바뀌면 큐큐이동
- Device Queue에서 인터럽트 발생 -> Ready Queue
- Ready Queue에서 CPU를 잡으면 Job Queue로 이동
- Job Queue running 상태에서 I/O를 잡으면 다시 Device Queue로
Schedulers
- Long-term scheduler (job scheduler): ready queue로 편입시킬 대상(new->ready) 결정하는 스케쥴러
- 새로 생성된 프로세스 대상이니까 빈번하게 발생하진 않음
- degree of multiprogramming: cpu를 잡아서 일을 조금조금 하고 있는 프로세스 개수
- long-term scheduler가 컨트롤
- degree of multiprogramming: cpu를 잡아서 일을 조금조금 하고 있는 프로세스 개수
- 새로 생성된 프로세스 대상이니까 빈번하게 발생하진 않음
- Short-term scheduler (CPU scheduler): ready 상태의 프로세스 중 어떤 놈에게 cpu를 줄까 결정
- Medium-term scheduler: 메모리 공간 확보를 위해 프로세스를 디스크로 swap out, swap in 해주는 것
- I/O bound process: hwp, ppt같은 사용자가 뭐 누르면 시작되는 프로세스, many short CPU bursts
- CPU-bound process: 한 번 시작하면 사용자가 입력 주지 않고 계속 계산하는 거, few very long CPU bursts
Context Switch
-> 프로세스가 돌다가 다른 프로세스로 변환되는 것
- 프로세스의 상태를 계속 저장해야돼서 멀티프로그래밍을 지원하는 os가 감내해야 하는 overhead 발생
- 동반되는 overhead: cpu switch 발생 시 캐시를 비워 -> 초반에는 계속 cache miss -> overhead 큼
Process Creation
- 사용자의 요청에 의해 생성(주체는 프로세스) -> UI를 관장하는 프로세스가 사용자 입력을 받아 생성
- 키보드 input을 받은 쉘 프로세스가 fork()
- tree형태의 가계도가 만들어짐
- 나를 만든 프로세스 = parent process
- 내가 만든(fork) 프로세스 = child process
- 웹서버의 경우 어떤 건 request, 어떤 건 response 같이 부모 자식 간 자원(동일 코드, 다른 부분 수행)을 공유하기도 함
- fork 로 프로세스 생성 시 address space에는 부모 꺼 그대로 복제
- exec를 호출하면 그때 독립하면서 address space를 채우게 됨
- fork하면 어떻게 구분을 해?
- 자식 프로세스 fork 시점을 정확하게 알아야돼
- address space가 똑같으니까 pc도 똑같아
- fork return value를 잘 봐야돼
- 부모한테는 자식 pid return
- 자식한테는 0 return

Threads

- lightweight process라고도 함
- code, data, files 등은 공유
- thread별로 각각 다른 부분 수행 -> registers, stack은 각자 가짐
- 장점
- 진도가 계속 나가니까 응답성 굳
- process는 각각의 address space를 가지는 반면, threads는 공유하므로 자원 활용의 효율성 굳
- process 여러 개 만들면 overhead 큼, threads는 memory copy를 하지 않으므로 경제성 굳
- multicore system> 하나의 프로세스는 하나의 코어, 여러 개의 스레드가 있는 경우 서로 다른 코어에서 돌 수 있어서 빨라짐 확장성 굳
- Kernel Threads: 커널이 만들어줌, 커널에게 일일히 요청, 답을 받아야 하니까 무겁고 느림
- User Threads: 유저 레벨에서 만듦, 커널의 입장에선 하나의 프로세스가 있을 뿐 thread의 존재 모름, 가볍고 빠름
한양대학교 강수용 교수님 운영체제 강의 내용 정리