- 운영체제의 구성요소 중 유일하게 별도로 판매되는 부분
- 2차 저장 장치를 다루기 때문에 굉장히 느림 -> 다양한 복잡한 기술이 들어감
File
- 데이터나 프로그램을 담는 그릇
- 구조
- None: words, bytes의 시퀀스
- Simple record structure: 한 덩어리의 데이터가 라인으로 구분되는 것
- Complex Structure: Formatted document, Relocatable load file
- OS, Program이 구조 결정
- File Attributes(File Metadata); 파일에 대한 정보
- Name: 데이터를 잘 표현할 수 있는 이름으로 지음
- Type: 데이터 타입을 보여주는 것
- Location: 현재 저장장치에 담겨있는 위치
- Size, Protection, Time, Date, user identification, ...
Directories
- 목적
- user 입장: 파일 정리, 그룹화하기 위함
- file system 입장: 어떤 파일의 유일한 이름을 결정할 수 있는 편리한 방법 제공, 같은 이름의 파일이어도 디렉토리가 다르니까 구별 가능

- Directory Entry
- 파일의 메타데이터를 저장하는 자료구조
- 파일 하나당 directory entry 한 개
- 파일의 데이터에 접근하기 위해서는 데이터가 어디 있는지 알아야 함 -> 파일의 메타데이터의 위치를 알아야 함 -> 디렉토리에 저장이 되면 디렉토리 위치만 알면 됨 -> 그 디렉토리 위치는 상위 디렉토리가 가짐 -> root에서부터 찾음
- 파일의 첫 번째 데이터를 읽고 싶음 -> 파일의 메타데이터가 저장된 디렉토리로 가야 됨 -> 데이터 접근 시마다 위치를 파악하는 과정을 거쳐야 함 -> 하드디스크 접근 필요 -> I/O 많이 발생
- file open이라는 행위로 파일의 메타데이터를 메모리에 올려 놓아서 데이터의 위치를 찾기 위해 매번 데이터를 찾기 위해 디스크에 접근할 필요 없음 -> I/O 줄일 수 있음
- directory entry cache 에 남겨뒀다가 또 접근되면 캐시에 있는 거 쓰면 됨
- 메모리의 메타데이터가 하드 디스크에 있는 원본 메타데이터에 반영이 되어야 함
- Directory Structure
- Directory entry는 filename과 inode를 가리키는 포인터를 가짐 -> 사이즈가 작아짐
- inode에는 메타데이터가 저장되어있고 디스크에 흐트러져있음
- Directory Implementation
- Linear list로 관리: 구현하기는 쉽지만, linear search를 해야 돼서 overhead O(N)
- Hash Table을 쓰자: filename을 input, 해쉬 함수의 output이 linear list의 특정 위치를 가리키는 포인터가 되도록
- Single-Level Directory: 파일 이름 충돌, 관련있는 파일끼리 Grouping 불가
- Two-Level Directory: 사용자별 디렉토리
- 한 사용자의 파일끼리 이름 충돌 가능
- 사용자간 이름출동 없음
- 한 사용자 입장에서 grouping할 수 없음
- Tree-Structured Directories: 어떤 곳에서든 subdirectory를 만들 수 있음
- Acyclic-Graph Directories: tree는 부모 노드가 한개, 그래프에서는 여러개일 수 있음
- 어떤 파일이 서로 다른 두 개의 디렉토리에 포함 가능하도록 함
- 파일을 copy할 필요 없이 포인터만 가리키면 됨
- 하위 디렉토리에서 상위 디렉토리를 subdirectory로 가질 수 있으면 cyclic, 없으면 acyclic
- traverse problem; 쭉 돌아볼 때 2번 접근됨
- delete problem; 더 큰 문제
Mounting
- 루트 디렉토리를 특정 디렉토리의 밑에 붙여주는 거
- 별도의 드라이브를 하나의 거대한 file system으로 관리 가능

디스크에서 File Data Allocation
- 2차 저장장치는 느림, 파일을 byte 단위로 읽으면 너무 느림 -> block 단위 관리
- 모든 2차 저장장치(USB, CD-ROM, SSD, 하드 디스크,...)는 block 디바이스
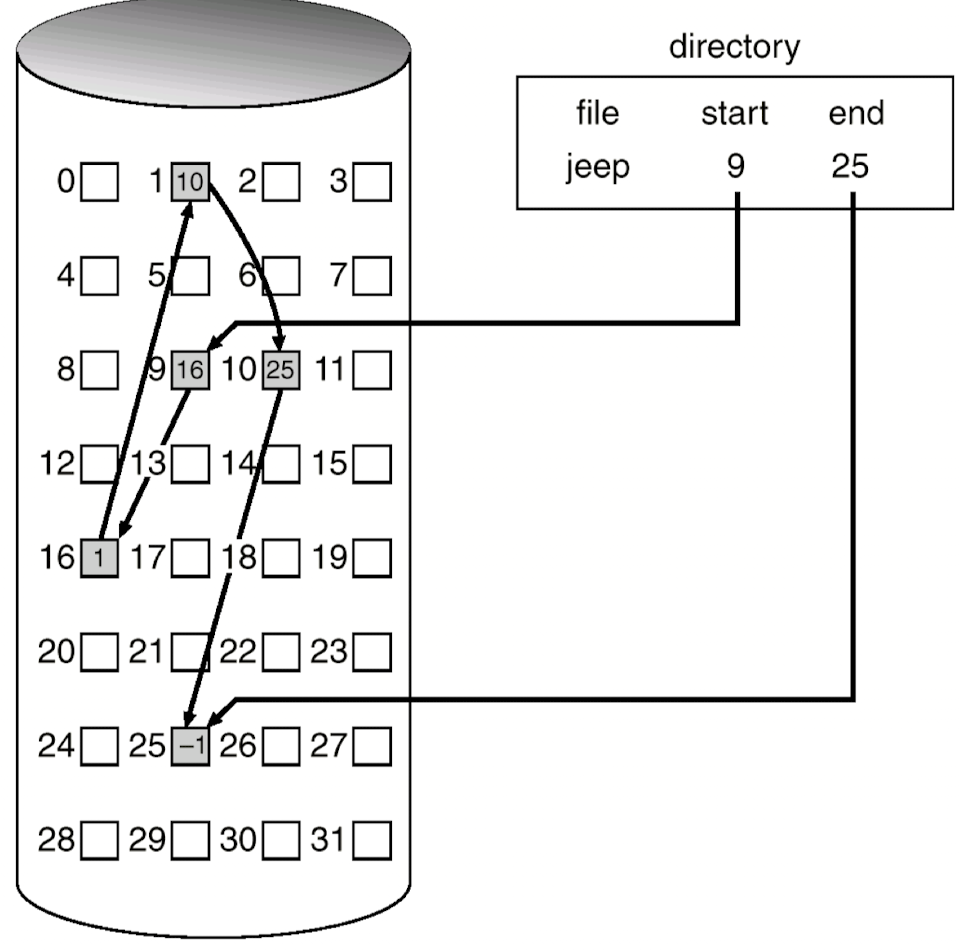
- Contiguous Allocation
- 파일 데이터를 디스크에 연속적으로 저장하겠다
- (+) 첫 번째 block 위치만 알면 모든 데이터 위치를 계산해서 알아낼 수 있음
- (+) 파일 하나를 읽을 때 쭉 읽을 수 있으니까 성능이 좋아짐; 동영상 같은 경우에 적절
- (-) external fragmentation 문제; 서로 다른 크기의 파일들을 할당/해제하다보면 짜투리 공간 생김 -> 그렇게 큰 문제는 안 됨
- (-) internal fragmentation 문제; 파일 크기가 커져버릴 때를 대비해서 미리 여분을 할당하는 경우

- Linked Allocation
- disk block을 linked list로 관리
- (+) 공간 낭비 X
- (-) random access 안됨
- (-) 매 데이터마다 disk seek(헤드 움직이는 행위)해서 I/O 효율성이 떨어짐
- (-) Reliability 문제; block 하나 유실 시 그 이후의 block들을 잃어버리게 됨
- (-) 포인터 공간 필요; 그렇게 크지 않아서 ㄱㅊ긴 함
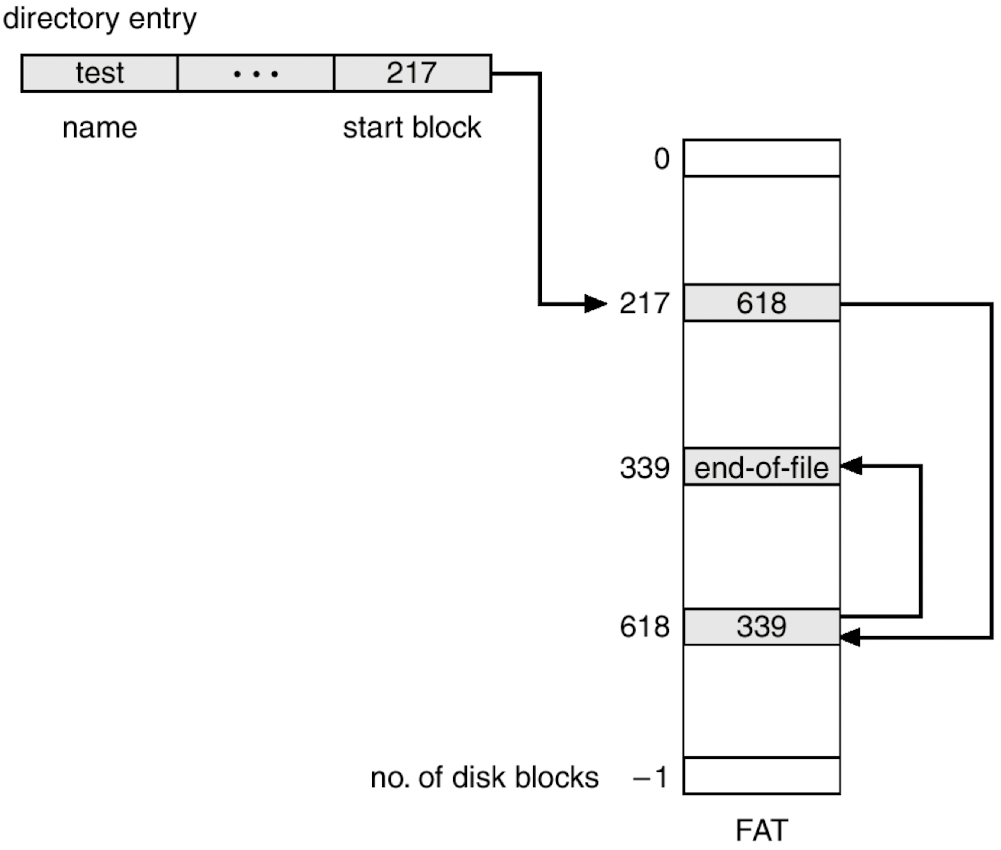
- File-Allocation Table(FAT)
- 디렉토리 엔트리에 파일 이름과 파일의 첫번째 block이 들어감
- block들을 따라갈 수 있는 자료구조
- (+) 부팅 시 메모리에 올려버리니까 메모리에서 모든 파일들의 위치 정보 접근 가능 -> I/O 오버헤드 감소
- (+) random access도 가능
- (-) FAT 잃어버리면 끝장 -> 보통 3개의 copy 유지
- (-) 파일 정보 변경 시 3개의 copy에 반영해줘야 돼서 조금의 오버헤드 발생
- Indexed Allocation
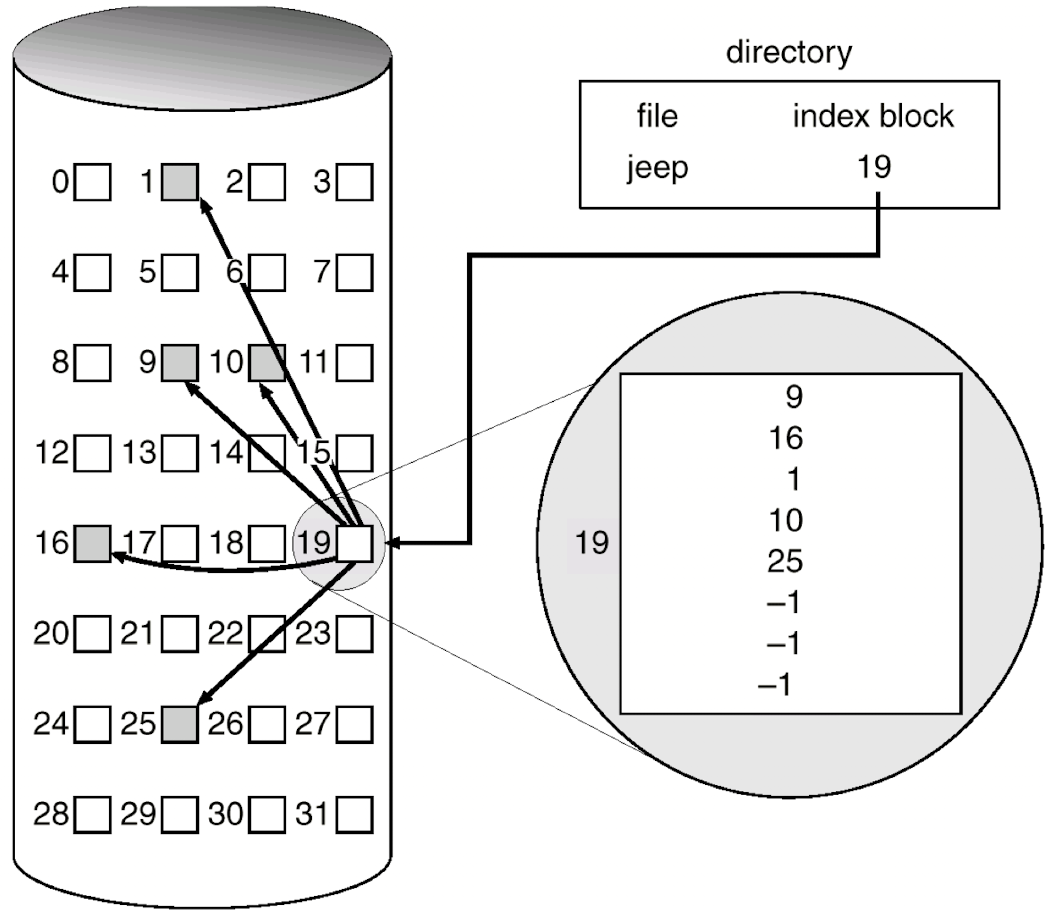
- 각 파일이 index block 가짐
- index block: 파일의 데이터가 저장돼있는 디스크 block들의 위치 정보를 포함하는 block
- index block 읽으면 파일의 모든 위치 정보 얻을 수 있음 -> random access 가능
- Index block이 하나의 disk block이니까 저장 용량의 한계가 생김 -> 확장
- 확장 방법 1. Linked Scheme - index block을 linked list로 관리
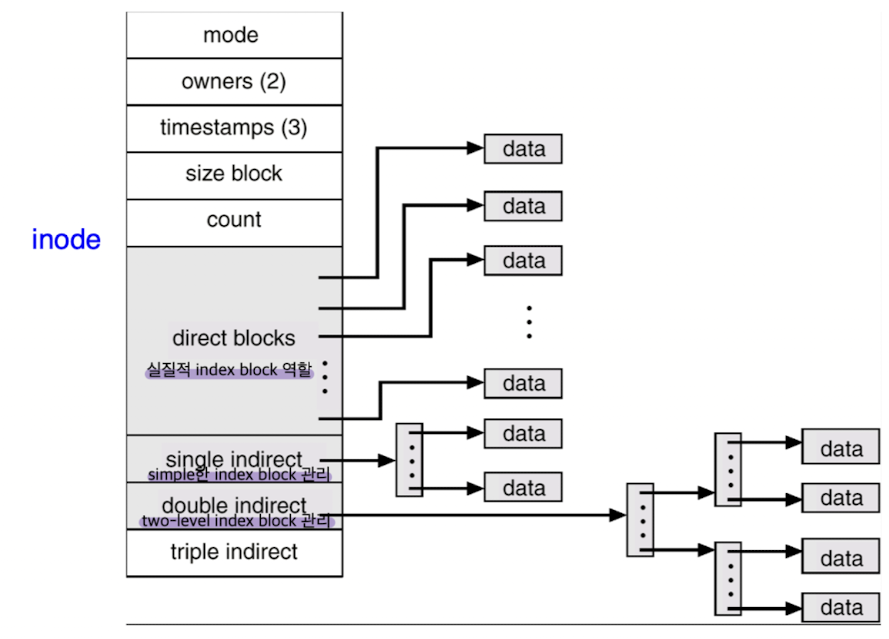
- 확장 방법 2. Two-level index - index block을 다단계로 구성, index block이 데이터 블록을 가리키는 게 아니라 index block을 가리키도록
- 확장 방법 3. Combined (EX. UNIX)
- inode: UNIX 계열 OS가 파일 메타데이터를 저장하는 자료구조
Free space management
- Bit map: 각 공간이 비어있으면 1, 사용 중이면 0
- 연속적으로 1이 나오면 contiguous allocation에 적합
- Linked list: 빈 block을 linked list로 관리
- 연속적 공간을 찾기가 되게 힘듦
- Grouping: 첫 번째 free block에 빈 block들의 포인터를 다 집어넣음
- 마지막 block은 또다시 index block을 가리킴
- Counting: 첫 번째 비어있는 block과 거기서부터 몇 개가 비어있는지 숫자로 관리
- 웬만하면 연속적으로 할당하자 하는 노력이 반영된 것
'운영체제' 카테고리의 다른 글
| [운영체제] I/O Systems (0) | 2024.06.11 |
|---|---|
| [운영체제] Mass Storage Structure (2차 저장 장치) (0) | 2024.06.06 |
| [운영체제] Virtual Memory(2) (0) | 2024.05.13 |
| [운영체제] Virtual Memory (1) (0) | 2024.05.06 |
| [운영체제] Memory Management (2) (0) | 2024.03.24 |



