- 산업 제어 시스템(Industrial control systems)의 결함, 사이버 공격 등 이상 탐지를 위해 다섯 가지 대표적인 시계열 이상 감지 모델 (InterFusion, RANSynCoder, GDN, LSTM-ED, USAD) 의 비교 연구를 수행
- 공개 데이터셋인 SWaT와 HAI 사용
- 기존의 머신러닝 기반 이상 탐지 연구는 정상 데이터만을 이용해 비정상 행위를 탐지하는 비지도학습 접근에 초점
- 환경과 데이터셋을 동일하게 하고 모델 간 비교 진행
Anomaly Detection in Industrial Control Systems
ICS 구조
- ICS는 산업 분야의 물리적 프로세스를 관리하며 ICT(Information & Communication Technology)와 결합함에 따라 사이버 공격 위협 증가
- ICS는 제어 시스템, 통신 네트워크 및 필드 장치로 구성됨
- 필드 장치는 물리적 프로세스와 연결되어 raw 데이터셋을 수집하거나 제어 시스템 명령 실행
- 센서는 시스템을 관리하기 위한 필수 정보를 얻기 위해 수처리 공정 측정
- 프로그래밍 가능한 논리 제어기(PLC)는 제어 시스템에서 전송된 프로그래밍된 명령을 수행하기 위해 센서 데이터셋을 입력 신호로 읽음
- 데이터셋은 유, 무선 링크를 통해 제어 서버로 전송되어 분석을 위해 데이터 히스토리언에 축적
- 인간 작업자는 표준 프로토콜을 따라 제어 서버에 액세스하여 데이터셋을 모니터링
- 데이터셋에 대한 정보는 인간-기계 인터페이스(HMI)에서 데이터 히스토리언(data historian)을 쿼리함으로써 제시
- 데이터 히스토리언; 일종의 데이터 수집 소프트웨어로서, 프로세스 데이터(예: 공장 온도, 압력 측정치 등)를 취합해서 디스크에 저장한 후, 보고나 추세 파악과 같은 분석에 사용할 수 있게 만드는 일을 함
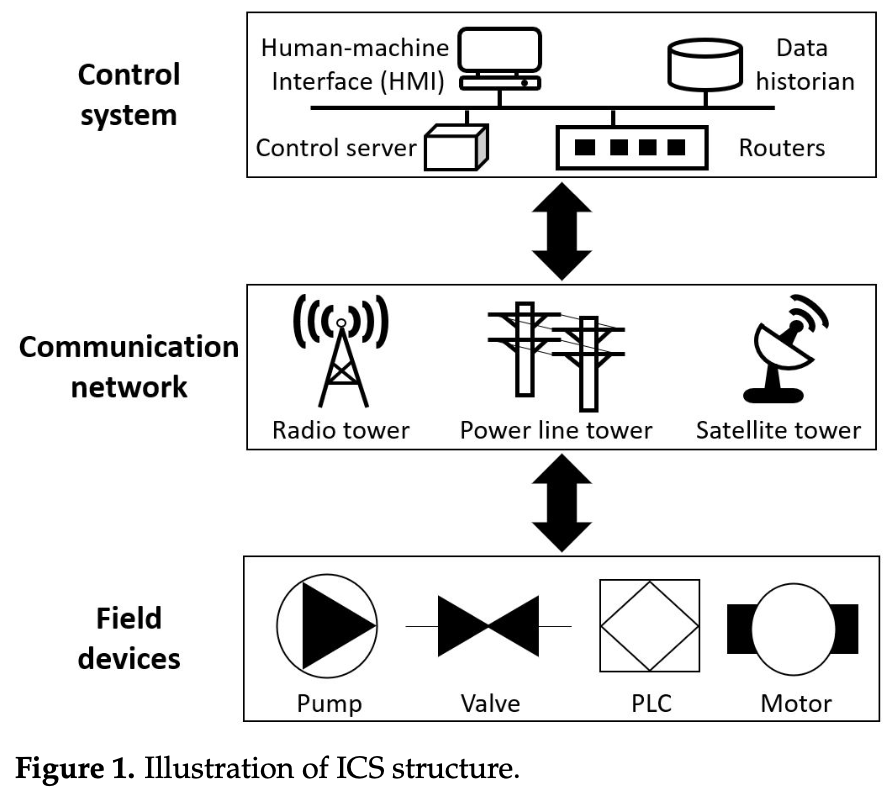
- 수집된 데이터셋에는 ICS에 대한 정상, 악의적 이벤트의 raw 센서를 읽는 것이 포함되어 있기 때문에, 비정상 데이터를 탐지하기 위한 지속적인 분석은 공격자의 행위를 이해하는 데 도움이 됨
ICS에서의 Anomaly Detection
- 산업 프로세스는 주어진 일의 일련의 과정을 수행하므로, 수집된 데이터는 시계열의 특성을 띔
- ICS 데이터셋은 고차원적이고 연속적으로 수집되어 multivariate time series(MTS), 다변량 시계열이라 부름
- 로그는 연결된 필드 장치에서 모든 순간 수집됨
- ICS의 MTS 데이터셋 이상 감지 접근 방식
- 각 시간 순간만다 예측된 값의 편차 수준 계산
- DNN은 동적 ICS 시스템의 비선형 관계(비례 X, 직선으로 관계 표현 불가)를 효과적으로 학습할 수 있기 때문에 이상치 감지 가능
- MTS 데이터셋의 비정상적 형태를 찾는 것에 중점; one-class 분류 모델이 적합
- 각 시간 순간만다 예측된 값의 편차 수준 계산
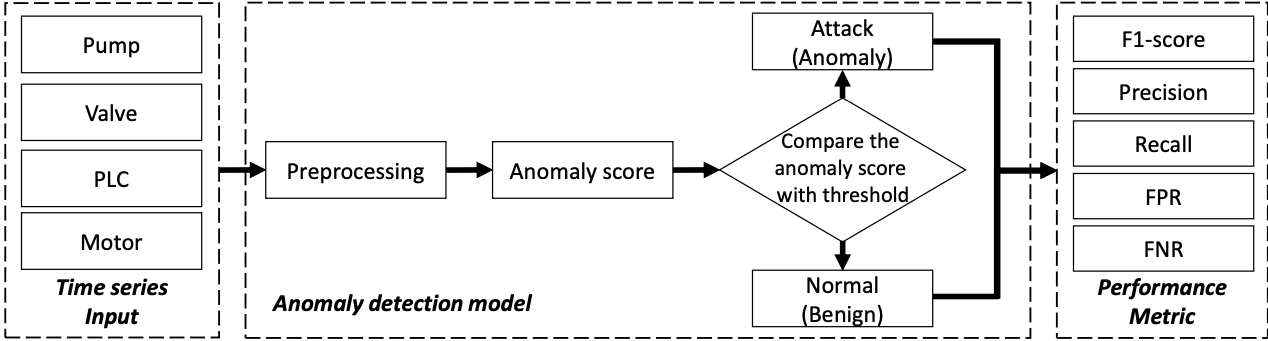
시계열 이상 탐지 프레임워크
- 공격자는 네트워크를 통해 필드 장치에 접근하고 대상 시스템을 완전히 이해, 정상 작업을 조작해 대상 ICS의 장애 및 고장을 유발함
- 공격에 대항해 머신 러닝 모델을 사용해 입력 시계열 측정치의 정상 패턴을 공격 행동과 구별 가능
- 딥러닝을 사용한 비지도학습 이상 탐지 프로세스의 3단계
- preprocessing
- 다양한 필드 장치(PLC, 펌프, 밸브 및 모터 ...)에서 수집된 raw 다변량 시계열 데이터는 노이즈가 있는 측정값, 누락된 값 및 이상치를 포함할 수 있음
- 이상 탐지 솔루션 개발을 위해 모델이 필요로 하는 정제된 데이터의 기준을 충족하지 않는 시계열 측정치는 버려야함
- 데이터를 모델에 입력하기 전 정규화 및 필털이과 같은 작업ㅇ르 적용하여 raw 데이터를 전처리해야함
- anomaly scoring
- 정상/이상 데이터 간 간격을 최대화하는 효과적인 점수화 방법을 정의하는 것 => 감지 예측 성능 향상
- 클러스터링 기반, 히스토그램 기반, isolation forest(데이터셋을 tree 형태로 나타낸 후 depth로 정상/이상 분리), 딥러닝 오토인코더의 재구성 오류 기반 등의 방법이 제안됨
- thresholding
- 이전 단계에서 계산된 점수를 기반으로 최종 결정(normal/attack)에 대한 증거로서 사용
- 데이터 포인트 분류를 위해 매번 계산된 점수와 임계값 비교 프로세스 진행
- 임계값 = ICS가 입력 측정 값을 승인할 수 있는 최소한의 점수 값
- 측정값이 임계값보다 낮을 때 이상 데이터(공격 행위)로 분류, 프로세스 거부됨
- preprocessing
데이터셋
- Secure Water Treatment(SWaT)
- 시스템 동작을 제어하고 모니터링 하는 전체 물리적 프로세스
- 첫 7일은 정상 운영 상태의 센서 데이터 수집
- 나머지 4일은 공격이 있는 상태의 센서 데이터 수집
- 공격자가 EtherNet/IP 및 CIP를 통해 전송된 데이터 패킷을 가로채고, 공격 유형은 총 41개
- Hardware-In-the-Loop(HIL)-based Augmented ICS(HAI) / 본 논문에서는 21.03 사용
- 증기 터빈 발전 및 양수 발전을 모방하는 HIL 시뮬레이터로 증강된 테스트베드에서 19일간 수집
- 첫 5일은 정상 운영 상태, 나머지 14일은 공격 상태에서 센서 데이터 수집
- 공격자가 패킷을 조작해 물리적 측정에 지속적 오류 발생시키며, 공격 유형은 총 25개
Evaluation
- 최적의 feature를 선택하기 위해 각 데이터셋 feature의 상태적 중요도를 분석하기 위한 XGBoost 알고리즘 사용
- SWaT 데이터셋에서는 flow transmitter, HAI 데이터셋에서는 turbine rotation이 가장 중요한 feature임
Evaluation Metrics
- 두 데이터셋 모두 불균형하며 낮은 비율의 이상치가 수집되었다는 점에 주목 -> 이상치가 10%면 모든 클래스를 정상으로 분류해도 모델은 90%의 정확도를 가지기 때문 => 성능 메트릭을 결정하는 것이 중요
- Precision(정밀도): 출력이 올바른지 잘못된지에 관계없이 새로운 데이터를 사용하여 테스트할 때 훈련된 모델의 출력을 중점
- 정상 샘플을 이상치로 잘못 예측할 때 (False Positives) ICS에서 정상 프로세스를 거부하게 만듦
- Precision = True Positive / True Positive + False Positive
- Recall(재현율): 실제 이상치에서의 오류에 중점
- 모델이 공격자로부터 이상치를 정상 데이터로 잘못 받아들일 때 (False Negatives) ICS 접근 권한을 잘못 부여하게 됨
- Recall = True Positive / True Positive + False Negative
- Fβ-score: Precision과 Recall은 임계값의 영향을 받아 둘만을 사용하면 부적절할 수 있기 때문에 둘의 조화 평균 사용
- 매개변수 β는 Precision과 Recall 간 상대적 중요성을 조정하는 데 사용
- β가 1보다 크면 Recall에 더 많은 가중치 할당, 1보다 작으면 Precision에 가중치 할당
- Precision(정밀도): 출력이 올바른지 잘못된지에 관계없이 새로운 데이터를 사용하여 테스트할 때 훈련된 모델의 출력을 중점
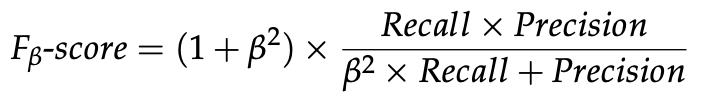
- 본 논문에서는 Precision, Recall, Fβ-score와 두 가지 오경보 메트릭은 False Positive Rate(FPR), False Negative Rage(FNR) 고려
- FPR: 실제 정상 데이터를 공격으로 예측
- FPR = False Positive / False Positive + True Negative
- FNR: 실제 공격 데이터를 정상으로 예측
- FNR = False Negative / False Negative + True Positive
- FPR: 실제 정상 데이터를 공격으로 예측
데이터 전처리
- 데이터 정규화(Normalization): 각 feature 값을 스케일링하거나 변환하여 동등한 기여를 하도록 하는 것
- 상수 특성 제외(Feature exclusion): 변하지 않는 feature인 상수 feature 제외
모델 최적화
- 각 모델의 하이퍼파라미터(사용자가 모델을 위해 설정하는 값) 최적화
- epoch: 훈련 세트의 모든 가중치 벡터를 업데이트하는 데 사용되는 측정 값
- batch size: 모델 가중치를 업데이트하기 위한 훈련 세트 샘플 수
- window size: feature 값에 기반하여 다음 시간을 예측하기 위한 입력 시간 단계의 길이 의미
- learning rate: error gradient를 줄이기 위한 스텝 크기
- 각 모델의 최고 F1-score를 달성하기 위한 최적의 임계값 탐색
- F1-score: 분류 모델의 성능 평가 지표
'AI' 카테고리의 다른 글
| HAI(HIL-based Augmented ICS) security dataset 이란 (0) | 2024.06.04 |
|---|---|
| [딥러닝] 딥러닝 기초 (0) | 2024.05.30 |
| [논문] WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation (0) | 2024.05.13 |
| [논문] EfficientAD: Accurate Visual Anomaly Detection at Millisecond-Level Latencies (0) | 2024.05.12 |
| [논문] TadGAN: Time Series Anomaly Detection Using Generative Adversarial Networks (0) | 2024.05.06 |



