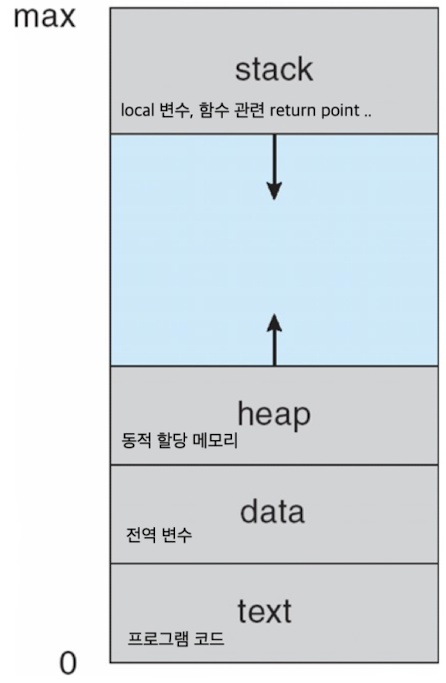
- 기본적으로 메모리 관리는 CPU가 프로그램을 수행할 수 있도록 만들어 주는 것
- 명령어 가져올 때 메모리에서 주소 가져옴 -> 효율적 관리 필요
- 메인 메모리는 느려, 캐시 사용
Binding
- 변수의 주소를 실제로 매핑시키는 것, 메모리 상 물리 주소를 변수의 주소를 매핑시키는 것
- binding 시점에 따라 3가지로 나뉨
- Compile time binding: 컴파일 할 때 매핑 -> 컴파일되면 프로그램 코드 안에 변수 주소가 하드코딩됨
- 프로그램이 무조건 커널 다음 번지에 올라간다고 해놓음
- 다른 컴퓨터에서 실행된다면 커널의 크기가 달라져 -> 프로그램 시작점이 달라져 -> 다시 컴파일해야함; flexibility 매우 떨어져
- Load time binding: 프로그램 시작 프로세스 위치 0번지라고 가정, 상대적 주소를 변수마다 binding
- 프로그램을 메모리에 탑재할 때(load할 때) 시작 주소 결정됨
- 변수 주소(상대 주소)에 시작 주소 더해주면 됨
- 멀티태스킹 가능
- 한 번 올라가면 주소가 정해져버리니까 실행 과정에 메모리 위치 이동 불가
- Execution time binding: 메모리 접근 시 실시간으로 주소 변환
- 메모리 로드 시점까지도 상대 주소 갖고 있음
- 메모리 위치 이동 지원
- 0번지부터 출발한다는 가정 하의 상대 주소를 실제 DRAM으로 바꿔주는 자료구조 필요 -> Address Mapping Table
- 주소 변환이 느려지면 프로그램 실행 시간 엄청 느려짐, 하드웨어 지원을 받아야 함 -> 주소 변환 담당 하드웨어 MMU(Memory Management Unit)
Base and Limit Registers
- 프로세스의 시작 지점(base), 길이(limit)를 저장하는 변수 필요
- 프로세스 수행 시 CPU register로 저장
Logical and Physical Address Space
- Logical address( = virtual address): CPU가 알고 있는, 논리적 주소 체계
- Physical: 메모리에 올라가 실제 DRAM의 주소를 갖는, 물리적 주소 체계
- 왜 분리가 되어 있냐? CPU는 실제 물리적으로 어디에 있는지는 몰라도 되고 논리 주소만 알고 있어라
- compile, load time binding은 컴파일 시, 메모리 탑재 시 변수의 주소가 코드에 박혀버리니까 CPU가 알고 있는 주소 역시 physical 주소와 같아짐
- execution time binding은 두 주소 체계가 분리됨, 대부분의 운영체제는 execution time binding 사용
MMU, Memory Management Unit
- logical address -> physical address 변환하는 역할을 하는 하드웨어
- 메모리 시작 위치는 base register(=relocation register)에 저장
- ? 그냥 덧셈 해주는 건데 하드웨어가 필요한가?
- paging 기법을 보면 단순 덧셈이 아니구나
- ? 일단 메모리에 주소가 올라갔는데 바뀔 일이 뭐가 있나?
- swap: medium-term 스케줄러가 프로세스 하나를 통채로 쫓아내 디스크로 보내는 것
- swap으로 쫓겨난 프로세스가 suspend 해제돼서 다시 메모리로 올라올 때 원래의 위치로 온다는 보장 X
- Backing store: swap된 프로세스의 주소 공간이 저장될 공간, 보통 디스크라고 부름
- 큰 데이터를 읽어 오고 내리고 하는데 빠르게 해야 함
Contiguous Allocation
- 메모리에 연속적으로 저장됨
- 그래야 base register에 logical 주소를 쭉 더할 수 있음

- 사용자 영역에서 프로세스가 들어왔다 빠졌다 하니까 중간중간 빈 공간이 생김, 빈 공간의 크기도 달라질 수 있음
- 빈 공간 = Hole, 관리하기가 쉽지 않음 -> Dynamic Storage-Allocation Problem
- First-fit: 프로세스가 들어갈 수 있는 첫 번째 공간에 넣겠다
- Best-fit: 프로세스랑 크기가 가장 맞는 공간에 넣겠다
- 프로세스를 넣고 남은 공간은 되게 작아서 쓸모없어질 확률이 높음
- Worst-fit: 무조건 제일 큰 공간에 넣겠다
- 프로세스를 넣고도 남은 공간에 다른 프로세스를 넣을 수 있음, 무조건 나쁘다고 볼 수 X
- Fragmentation: 짜투리
- External fragmentation: 할당이 안 돼서 사용 가능하지만 너무 작아서 쓸모없음, 실용적이지 않음
- Internal fragmentation: 할당을 했는데 프로세스가 사용을 안 함
- 1000바이트가 필요한 놈한테 1024바이트를 할당해줌 - 24바이트가 사용이 안 되니까 internal fragmentation
- external fragmentation 다 모아, 밀어 붙여서 - compaction, 메모리 카피가 계속 필요해서 overhead가 너무 큼
Paging
- 메모리, 주소 공간을 모두 같은 사이즈로 나눔
- external fragmentation이 일어나지 않도록
- 매커니즘
- 똑같은 크기의 블록으로 잘라, frame
- 주소 공간도 똑같은 크기로 잘라 page
- frame에 page를 집어넣어
- 각각의 page가 어느 frame에 있는지 알아야 됨 -> page table에 정보 저장
- 비어 있는 공간들도 frame 단위로 비어 있어서 internal fragmentation은 발생하지만 external fragmentation 발생 X
- 다 흩어져 있어서 주소 변환이 복잡해짐
- 페이지 사이즈를 2의 n승으로 결정하면 logical 주소의 비트를 분할해서 페이지 번호와 페이지 내부의 오프셋으로 나눌 수 있음
- logical address space: 2^m, page size: 2^n


- page table을 이용해 주소 변환이 그렇게 복잡하진 않음
- page table 정보는 어떻게 만드냐? => Free Frames
- OS는 비어있는 frame들을 관리
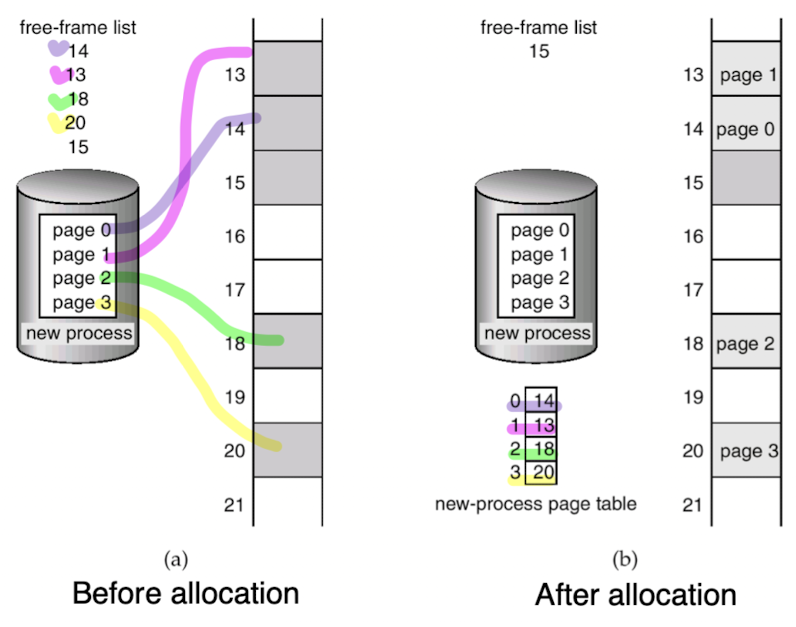
- 만약 free frame이 없으면? => virtual memory
Page Table 구현
- page table - 메인 메모리
- page table base register - page table 위치 저장
- page table length register - page table 길이
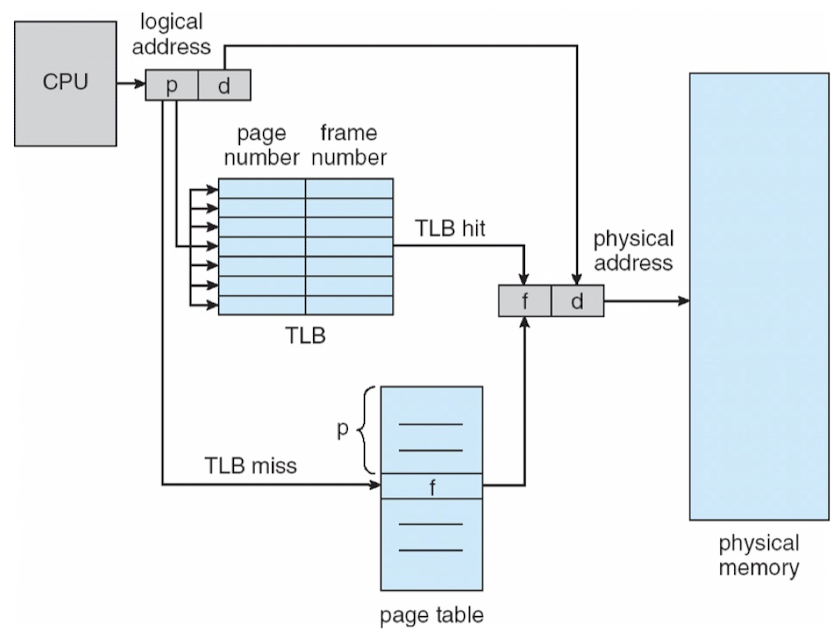
- page table로의 접근 1번 + 해당 페이지로의 접근 1번 = 총 2번의 메모리 접근 필요 => CPU 입장에선 되게 느림
- paging 기법의 이점을 포기할 수 없어서 등장한 게 TLB, Translation Look-aside Buffer
- 캐시같은 개념, 일부 정보를 올려놓은 것
- TLB에 페이지가 없으면 메모리로 가야 됨 -> TLB에서 거의 모든 페이지 변환이 일어나야 함
TLB = Associative Memory
- TLB는 띄엄띄엄 페이지가 들어있어서 위에서부터 뒤져서 찾아야 함 <= TLB 접근 횟수 늘어나야 하는데 이렇게 하면 너무 느려짐
- 그래서 일반적인 접근 방식으로는 효과 X
- 한번에 모든 페이지를 검색하는 특별한 메모리 사용
- 주소 변환 과정
- page table에서 번호 찾아 -> TLB 확인 -> 없으면 page table에서 frame 번호 알아내서 접근
- 많은 경우에 locality, 참조 지역성 때문에 TLB에서 frame 번호를 알아낼 수 있더라
- 프로세스는 여러개여도 TLB는 1개라서 context switch하면 TLB flush 됨, 텅텅 빔 - 직후에는 CPU가 메모리에 접근할 때마다 접근되는 페이지가 TLB에 올라옴
- Effective Access Time, CPU가 메모리에 접근해 원활하게 데이터를 가져오는 데 걸리는 평균 시간
- Associative lookup (TLB lookup 에 걸리는 시간): α
- 메모리 접근 시간 : β
- TLB Hit 비율: ε
- Paging 기법 사용하지 않으면 메모리 접근만 하니까 EAT 값은 β값과 비교됨
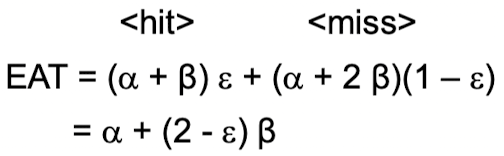
Memory Protection
- 잘못된 주소 접근 시 막는 protection 기법
- 각 page table entry에 protection bit(valid-invalid bit) 사용; 각 페이지가 legal한지 illegal한지 확인
- 이론적으로 가능한 최대 크기
- OS의 주소 체계와 관계, 32비트면 0~2^32-1번지까지 주소 존재
- 프로세스는 이론적으로 0~2^32-1 까지 크기 가질 수 있음 - 4GB
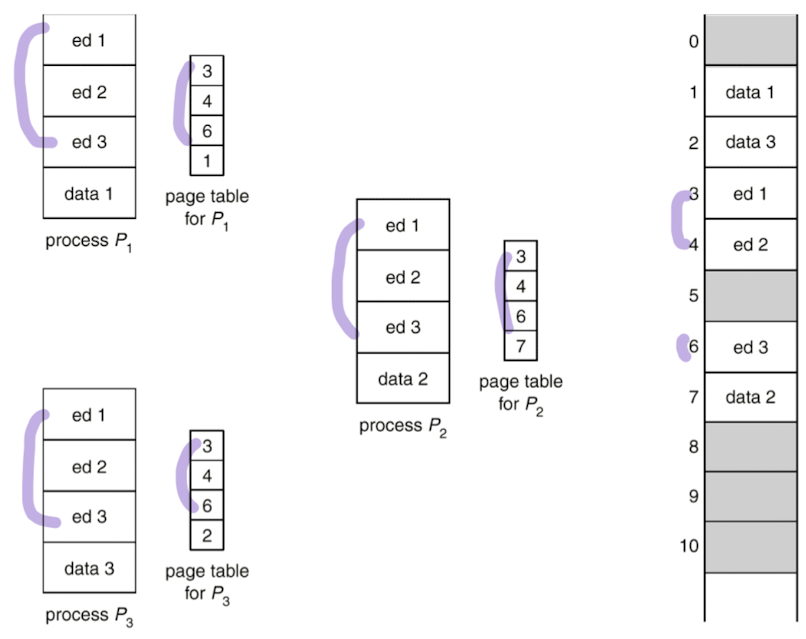
Shared Pages
- Paging 기법의 큰 장점: 페이지 공유가 가능해짐
- ex> 학생들이 서버에 붙어서 과제하는 경우
- gcc 컴파일러를 사용한다고 했을 때 text section은 똑같을 것
- 다른 프로세스가 내 영역의 text section에 접근해서 같이 읽으면 되지 않냐
- 각 프로세스는 editor를 공유하고, 데이터만 각자의 것을 갖고 있음
한양대학교 강수용 교수님 운영체제 강의 내용 정리
'운영체제' 카테고리의 다른 글
| [운영체제] Virtual Memory (1) (0) | 2024.05.06 |
|---|---|
| [운영체제] Memory Management (2) (0) | 2024.03.24 |
| [운영체제] Deadlocks (0) | 2024.03.12 |
| [운영체제] Process synchronization (2) (0) | 2024.03.06 |
| [운영체제] Process Synchronization (1) (0) | 2024.02.27 |



